Mitigating the Data Bullwhip
Handoff management is the only way to escape data supply chain inefficiencies


I have greatly enjoyed posting about data on Medium these past 3 months. Medium may be the only reality-based platform left.
Data Twitter is and has always been full of scam artist after scam artist.
Data Mastodon is no better. It’s the same exact hucksters as Data Twitter.
Data LinkedIn is even worse. It’s a sea of data influencers re-posting the same content every 4 weeks. It’s gotten so bad we’re at a point where data ‘thought leaders’ who have been granted CEO and Founder status by the Data VC cartel are out here gaslighting analytics engineers about the number of appropriate tables in a cloud data warehouse.
It’s comedy gold.
Data Reddit is nonsense too, a true cesspool of data disreality, full of the sexist garbage I’ve had to put up with my whole career and the embodiment of why I run my own firm and make quadruple or more what I would on one of these cesspool data teams.
I’ve even been called the ‘hate lady’ when people share my Medium articles on Data Reddit.

Yes, it may be the case that Lauren’s Medium account is the one final bastion of reality in the slew of nonsensical data content on the distributed internet cloud graph mind of scam after scam. Interest rates are rising, but they are not high enough just yet.
Welcome to data reality.
The Hate Lady is glad you are here, and we will sally forth.
Breaking Up the Data Supply Chain Bullwhip
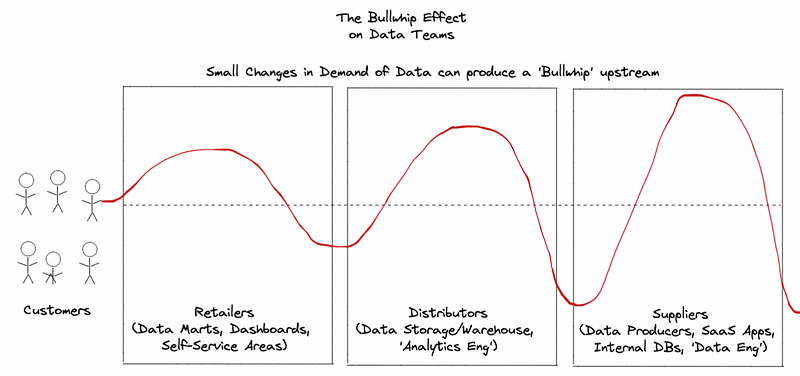
In the supply chain world, there is a phenomenon known as the Bullwhip Effect, which results from variance in end customer demand and amplifies demand variability upstream.
The data supply chain within your company likely operates the same way.
Here is how the Bullwhip Effect works. Put simply, if one alcoholic customer starts ordering cartons and cartons of Pinot Noir from his local wine retailer, this will result in this retailer ordering more Pinot Noir from their distributors. Instead of getting 10 cartons of Pinot Noir a month, they will now procure 15. Then, the distributors will notice that Pinot Noir wine is seeing an upswing, and they will seek to capture profit. They will raise prices and/or buy more Pinot Noir from their suppliers, who will also notice the upswing. The suppliers, who are distant from the end customer, may then decide to shift their own production. If the distributors are upping their orders of Pinot Noir, and this is holding, the suppliers may decide to uproot some of their Chardonnay grapes in the vineyard and replace them with Pinot Noir grapes. Now they will put 40 cartons of Pinot Noir into the supply chain.
Now, what has happened here is that the supplier is making an outsized bet based on the distributor’s purchasing habits. But the distributor’s purchasing habits are the result of the retailer’s purchasing habits. The retailer’s purchasing habits are the result of one alcoholic customer overspending on Pinot Noir at that retail location. So the entire supply chain is affected, based on limited information about what is actually causing the upswing in demand.
But what if this customer decides one day to switch to Cabernet Sauvignon?
Well, now you’ve got a supplier sitting on excess Pinot Noir, a distributor sitting on excess Pinot Noir, and potentially a retailer sitting on excess Pinot Noir.
It will have to be marked down across the supply chain. The retailer will feel pressure first, then the distributor who has likely started hoarding Pinot Noir, and then the supplier who is now sitting on acres of newly planted Pinot Noir grapes and who incorrectly believes demand for Pinot Noir to be greater than what it actually is.
Ah, the Bullwhip Effect.
The whole thing is more complicated than this simple example, of course, with more players and iterations. Upstream parties can smooth out demand shocks with debt or equity financing or economies of scale. They can also hold inventory depending on the durability of what is being sold.
But the point is simple: shocks in demand on the consumer side will inevitably lead to outsized efforts upstream, when each layer of the supply chain has increasingly weaker information about actual customer demand. The analyst/operations person is closest to the business. The analytics engineer is a layer back. The data engineers and software engineers are one layer further obfuscated from the customer.
In the capital ‘D’ Data world, this is pretty readily present in most organizations I’ve worked with, of all sizes and across industries.
In fact, this whole data dance is so inefficient that I fundamentally believe that most of the distributor layer is completely unnecessary overhead, and only functions to exist because suppliers and consumers do not interact in most organizations.
I’ve previously gone over reasons why this happens — the consumer class does not want the responsibility of interfacing with the producer class, and thus requires a middleware layer in the middle to create the assets they use.
But I think we’re over the data human middleware Modern Data Stack layer. It’s already burning to the ground with data team layoff after layoff, and I see no reason why it won’t continue for a while over at least the next six months.
Just as a number of brands figured out that they could go direct-to-consumer a decade ago, so too are digital native and tech data teams figuring out that they actually don’t need to do all that much work in the distribution (cloud data warehouse) layer. The reckoning is upon us, and I for one am quite excited.
Removing Distributors from the Data Supply Chain
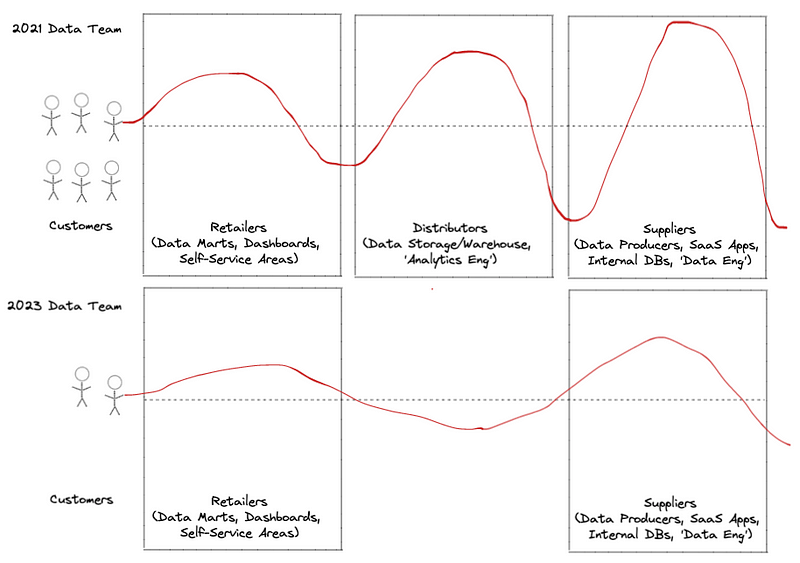
As we approach 2023, the fact of the matter is that the amount of data consumers is contracting. There are simply fewer people making requests of data teams, because these people have either been fired or were never hired in the first place, which decreases the demand on data teams and smoothes out the Bullwhip Effect.
While the 2021 data team would make lots of models and infrastructure to support dozens to hundreds of stakeholders, the 2023 data team should primarily focus on executive leadership decisions that can move the business and not dozens of reports in support of mid-level stakeholders. This is a lot of higher impact work, but likely a lower volume of work.
Further, pure ELT — relying on a vendor to ingest data to a central storage location, then managing schema and definitions after the load — will die off at many companies.
ELT relies on a high number of data employees configuring data analysis ‘close’ to the end stakeholder. But if many of the stakeholders are no longer needed, what is the point of having all of these analytics engineers ELTing?
Fewer people to crack the bullwhip = fewer shock hires to address the volatility of whip cracks. It’s simple.
Further, there are plenty of great ideas that the current technology space seems to think they have invented, which are growing in popularity and adoption. Of course, many of these things have been in place for many years at many enterprise companies, but we don’t seem to ever want to talk about that.
One is the concept of the schema registry, or the forefather of ETL, which is apparently catching on. Meta seems to have adopted some of this. It’s not that hard. At scale, you need to maintain a library or registry of schema. The data and attributes that exist there should have semantic meaning to a real world event, and this semantic meaning should be defined before the data ever gets to a cloud data warehouse or a BI tool. If you can define entities like the customer, the order line, the supplier, that’s even better because now you don’t have to waste analyst time and cloud credits resolving entities inside the cloud data warehouse.
Doing this removes 90–100% of the in-warehouse transformation needed. It saves a ton of money, as you would not be using SQL in the cloud data warehouse to patch together several layers of transformations to make a table — you’d just drop the table in complete.
Then, by doing this, you can start managing budget and removing the distributors from the Modern Data Stack supply chain. You can fire these people, save hundreds of thousands or even millions of dollars, and save tons of money on warehouse costs, just by defining and shaping and schematizing your data before you put it in the cloud data warehouse, like most profitable, scalable, EBITDA-run businesses do.
In doing this, you’re really only dealing with two parties in the data supply chain — one, the data engineers or whatever titled people are creating these tables from schema management, and two, the analysts who sit close to the business. There’s no need for the middle step at all.
Also, for most modern tech and digital native types of companies, most of these tables should look like event streams based on the activity or entity in question. Storage in the cloud data warehouse is cheap, so why not drop in already modeled data pegged to the specific events and entities that run your business?
It’s comedy how much over-correction occurs today with 3–5 layers of in-warehouse, manually written dbt SQL. That’s going away — nobody can afford it, and frankly the only companies that have even been able to afford it the past few years are mostly VC-backed unprofitable businesses.
When EBITDA dominates, there’s less analytics engineering and less middleware jobs available.
Handoff Management is the Way Forward
One of the biggest ruses of the low interest rates years is the idea that this data team human middleware layer should bloat in terms of headcount and power. As such, these teams have led to a proliferation of their own tools to handle the 15,000 tables that apparently the average Modern Data Stack team has in place.
- Atlan: a data catalog that helps these teams manage and define metadata in the 15,000 tables they have in place
- Monte Carlo: a data observability solution that helps these teams observe the 15,000 tables they have in place
- Datafold: a data testing solution that helps these teams understand column-level lineage and data diffs among tables, which is relevant because dbt does not have column-level lineage or the ability to do data diffs, and these teams use this for the 15,000 tables they have in place
And so on.
But the problem for the business is that these are all solutions that have nothing at all to do with handoffs. They have nothing at all to do with cross-team operations. They are just tools that exist within the data team to help the data team middle management layer do more middle management. It’s like getting a Lean Six Sigma Yellow Belt.
Back in reality, the only actual data problems are those that deal with handoffs, from which change management arises.
All that actually matters to keep the bullwhip at bay is managing to handoffs, as we began to cover here.
The Retailer <> Customer Handoff
This handoff is based around deliverables that manifest as data assets — reports, tables, dashboards, and similar, which are used by business stakeholders to make impactful, directional decisions.
This handoff is based on the validity, classification, and ownership of these assets. Just as a human can only have meaningful relationships with a handful of people, so too can executives only have meaningful relationships with a small number of decision support data assets. They cannot and will not and should not have 50 reports at their disposal.
Building the nth dashboard, and the pipelines to support it, is low impact, especially if the customer is not in a position to meaningfully move forward an initiative that impacts the business or a major P&L.
This is why control of sprawl is important, as is the joint accountability of retailers (analysts) and customers (business stakeholders) to certify assets as correct.
If dashboards are not actioned on, they may need to be deleted or removed, along with the pipelines that underlay them.
If you have more dashboards and loose spreadsheets derived from your data warehouse than you have total employees at your company, you may have already lost, or you at least need to clean up.
Building this mutual accountability between customer and retailer is key to preventing the Bullwhip Effect from becoming too strong, and I am a big fan of what Workstream is doing to help build this mutual accountability between data teams and end customers.
By creating an interface to collect assets and allowing the business and analysts to interact, the amount of cruft and excess data needs goes away very quickly and the most important analyses and business drivers rise to the top. This is 100x more valuable to most businesses than a data catalog that documents hundreds to thousands of tables.
How many dashboards are needed to run your business? It isn’t 500, which is probably how many Looker reports you have two years into adopting Looker, with two full-time analysts supporting.
So what are you doing? Focus on the handoff.
The Supplier <> Retailer Handoff
There are many solutions that have come about in the past two years around database replication, SaaS data extraction, and better ways to manage file transfers.
However, the Bullwhip Effects that result in bloat in my experience most often arise from attempting to sync data directly from SaaS applications — ERPs, ticketing systems, marketing platforms, order management systems, etc.
While the major 100 or so SaaS apps are covered by solutions like Fivetran, the main issue is that Fivetran and similar competitors support a library of connectors that aligns to their TAM. They have build a set of connectors to serve many customers. If you use SaaS apps that are not important to lots of companies in the market but may be extremely important to your business, you are out of luck. There is no longtail coverage, and it’s not even economical for Fivetran or similar to attack each nth connector as most will be net negative.
However, there are a number of solutions I am excited about that address this issue, including Prequel.
The premise is simple: you as a SaaS PM or founder don’t want to expend effort on your API. At some point, at least a few of your customers are going to start running GET requests to list data and drop it into their cloud data warehouse. But because you don’t treat your API as a first-class citizen, these customers struggle and waste lots of time. You then have to make a decision — will you improve or throw more resources at your API, or will you not and potentially underserve these customers?
Prequel shines by offering a solution to these applications that allows them to simply sync customer data to the customer’s destination of choice. No more rate limiting, pagination silliness, or anything. It’s just the simple transfer of data.
Bad application data — whether third-party SaaS vendors or even internal applications with bad APIs — causes a significant amount of headache for data teams. By removing these barriers, the application can function purely as a supplier of data in the customer’s data supply chain, with limited distribution resources needed.
I am very excited to see how Prequel and similar solutions develop, and I truly believe the days of wrangling poor APIs with poor documentation may finally be coming to an end, and along with it the hours of wasted time that these applications pass off to the customer.
Mitigating the Bullwhip
At each stage of the data supply chain, there is ample opportunity to overcorrect with solutioning and headcount and embrace the Bullwhip Effect of data customers placing orders to data functions. However, we are simply no longer at a time when data leaders can continue to let the Bullwhip Effect blow up their budgets. Hiring an extra analyst, then two extra analytics engineers, then some data engineers is something that cannot succeed going forward.
Data leaders will do well to consider how much ‘middleware’ work their teams are doing, and make cuts accordingly. Additionally, most data professionals currently doing a lot of middleware, distributor-type work would do well to either move deeper in the tech stack toward data engineering or move toward actual business analysis, or perhaps both.
Many tech companies are eschewing their data warehouse dedicated teams, and the savvy data professional will do well to broaden their skills.
The question for data leaders and data professionals of all sorts is simple: Do you want to be a rock band delighting your fans, or do you want to be Ticketmaster throwing markups and bureaucracy and hidden costs at customers you couldn’t care less about?
For more information, please feel free to check out the following:
- Questioning the Lambda Architecture by Jay Kreps
- The Rise and Fall of Crappy Data Products by Bart Vandekerckhove
- Implementing Data Contracts at GoCardless by Andrew Jones

