The Great Cloud Data NRR Squeeze is Going Swimmingly
Last month, on April 19, dbt Labs published “The Next Big Step Forwards for Analytics Engineering,” a rambling, jargon-laden puff piece…


Last month, on April 19, dbt Labs published “The Next Big Step Forwards for Analytics Engineering,” a rambling, jargon-laden puff piece that lays out how dbt Labs plans to remain solvent as a business. At the core of this narrative is model sprawl, or SQL sprawl, or stacked CTE sprawl — the proliferation of objects, tables, views, all referencing other objects, tables, views. All of these things, this stuff strung together with dbt. These are really just cash flows made from breaking down data schemas then rolling them back up again.
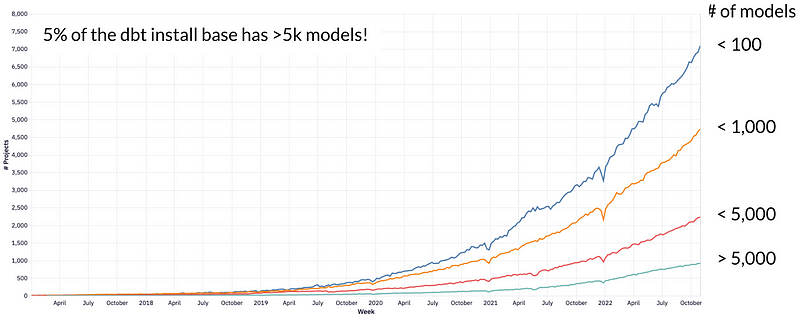
The narrative:
- Many organizations that have invested in dbt (the products and headcount to support) have increasing sets of SQL sequences over time
- Several years ago a big project would be 150 or so models, but today that number is 1,000 and an appreciable number of customers have over 5,000 models
- This is not a problem because software engineers have systems that grow in complexity
- dbt Labs’ offerings do not currently allow users to fully work like said software engineers with systems that grow in complexity, but there are a few plans for the future and new features and here are a few of them
Now, this all may sound good and dandy to you if you were born yesterday, but really what is going on here is the game behind the game: compound interest, or compounding debt obligations if you look at it from the customer side.
What is laid out in this article is no different than a financial institution offering advice in marketing materials that consumers carry more balance on their credit cards month to month, and then pay interest on it, while simultaneously adding more balance.
Could you imagine getting a pamphlet in the mail that sounds something like the below?
“At the Bank of The Yukon, some consumers like to run up their balance! A few years ago a big balance was $150, but did you know that many of our users actually like to carry a few thousand dollars these days? In fact, 5% of our customers even carry $5,000 over and pay interest! We’ll teach you everything you need to know on this upcoming community webinar.”
You should be able to look at “The Next Big Step Forwards for Analytics Engineering” and see that this is a scam — it is quite literally a predatory lending scheme.
The Credit Scam of Marketing to Junior Developers
In the United States, predatory lending to consumers is often wrapped up with too-good-to-be-true marketing primarily aimed at two groups: young adults and immigrants — those with less experience dealing with sophisticated finances. You get them hooked in early and locked into payment obligations, then you bleed them out over several years, with each payment higher than the first.
You always bleed your mark over time, not all at once.
In marketing bottoms-up to junior analysts and data engineers and first-time managers, most of whom are young adults or immigrants on various visas, dbt Labs is playing the same game as a predatory lender, only instead of going after a consumer’s bank account here they are trying to tap into the corporate treasury of their customer base and return this money back to the cloud data warehouse.
Marketing weak, quick-to-market products to create IT lifestyle brands for junior engineers is nothing new.
This piece offers a narrative of how MongoDB pulled off this playbook over a decade ago. It should be required reading for anyone working in developer-type jobs, and that goes double for any first-time managers.
Give it a read. How much of The Playbook sounds familiar to anyone in the current “Modern Data” world?
- Strategic creation of anointed advocates and community brand ambassadors providing “neutral” user-generated content
- A large amount of “engineering” content around the ecosystem is just marketing by and for junior developers
- Control of messaging around one specific stack, reinforced by conferences and community groups where the messaging can be sanitized and controlled
- Portfolio companies of stack’s VC investors in other verticals adopt the technology and produce early thought leadership
- Business Insider articles used as “proof” of the stack’s success
- Products do not meaningfully improve or grow with customers; customers are left holding the bag and have to re-platform with large consequences since basic features were missing the whole time
The whole thing is funny. It’s the same playbook Andreessen Horowitz and Amplify Partners run with dbt, Fivetran, Census, Hightouch, Hex, and 10 other toys with a bunch of influencers running around. Seriously, give this a read.
Most of B2C fintech, for example Buy Now, Pay Laters, operate under the same underlying principle:
- A company loosens lending standards below what “traditional” finance allows. Dollars are available to people and entities with lower credit scores, missing paperwork, or otherwise not able to get access to loans or favorable terms from the “traditional” system.
- People show up in droves because they have access to dollars previously withheld from them. This is deemed growth.
- New VC investors come along and mark up the value of the company and throw more money in to fuel the engine of growth. But where is the growth coming from? Well, it’s coming from increasingly uncreditworthy people. Growth is increasingly a function of riskier and less sophisticated users.
- 2–3 years into all this growth, growth, growth a number of customers realize they are paying usurious fees and interest. They get mad and take to the internet.
- New customer growth slows. The later investors are underwater, holding the bag because the Serviceable Obtainable Market has exhausted.
- The founders have taken money off the table by this point. They’ve made at a minimum a few million dollars. The VCs disproportionately run the company now and the later ones are underwater on their investment. The only way to keep the money coming in is to raise interest, fees, and/or any other costs on existing customers, many of whom are several years into a compounding payments scheme, paying interest on interest.
Congratulations. This thing that was an alternative to the evil banking system (which is not without its problems) is now a bank, and not a very good one.
When you loosen lending standards — for dollars, for data pipelines, for determining what an “engineer” is — you generate growth but you also create incremental debt in the market, and someone has to pay that debt and the interest.
The Great Consumption Model NRR Squeeze
At the root of most of the nonsense going on right now on the cloud is The Great Data Cloud Net Revenue Retention Squeeze.
Consumption-based NRR of Snowflake and BigQuery is what holds the whole ecosystem together. Really, it’s more Snowflake as they are accountable to Wall Street and less so BigQuery which is a very small item in the much broader Alphabet portfolio. Databricks is also there now to an extent.
You can see the model laid out in a chart by C3.ai about how consumption model revenue hits a J-curve vs. subscription revenue at first, then in Year 2 exponential growth kicks in. By Year 3, consumption revenue beats subscription revenue and it grows exponentially.
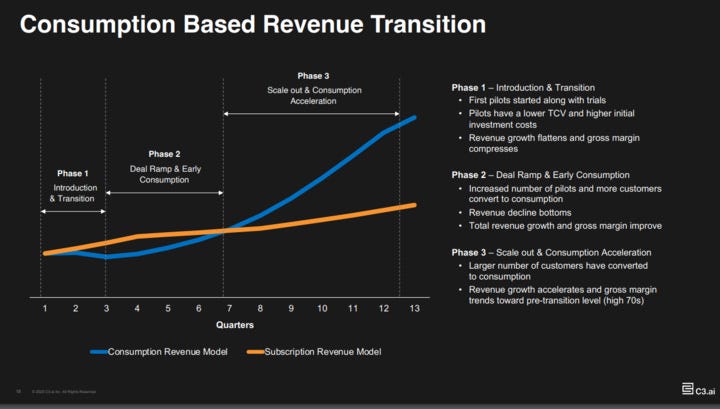
Snowflake has incredible NRR. They’re making more period-over-period off existing customers than anyone in the game.
But where does Snowflake’s industry leading NRR come from?
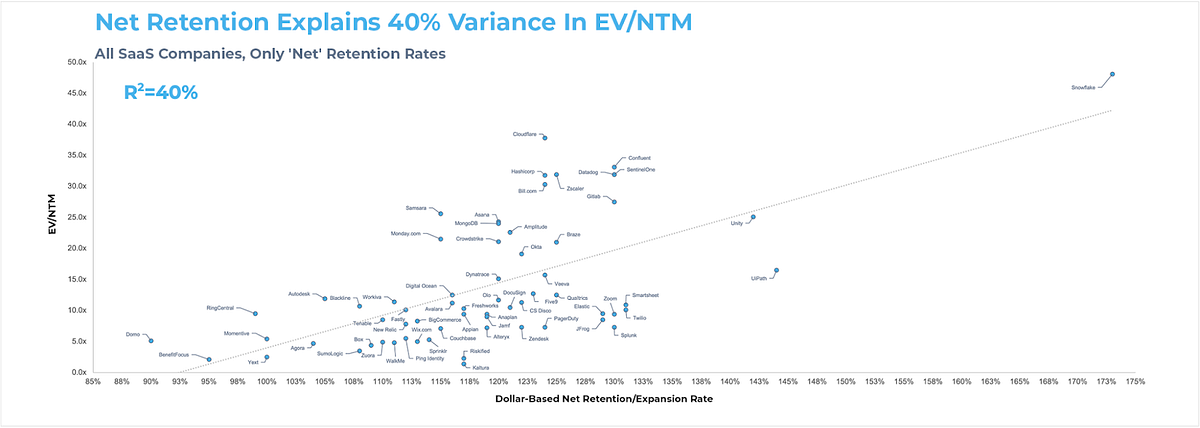
Well, Snowflake’s fantastic, wonderful, amazing, awesome, investable NRR comes from two things.
First is the fact that established, larger organizations and enterprises doing migrations from Oracle or Teradata or similar over to Snowflake quite literally often take longer than a year to complete the migration of workloads over to Snowflake and other services. The baseline period for NRR is shorter than the time it takes to complete the project to move a fixed set of workloads/pipelines.
For example, if an enterprise wants to move 500 workloads/pipelines off their Oracle set-up and instead go with S3 on AWS then run through Snowflake via Snowpipe or similar, they may only get around to 200 of these in the first year. This is about 4 workloads/pipelines a week to develop, do UAT, and run through the whole SDLC. In the second year they may migrate another 200, so that’s 400 total by the end of year two. In the third year they may migrate the remaining 100.
So this project would take 2.5 years to fully complete. Of course NRR looks good here.
Second, smaller and mid-market companies on the dbt Kool-Aid make exponentially growing cash flows. They lean fully or heavily into ELT instead of ETL. They hire large data teams to handle all of these atomized, highly normalized objects to roll them up and down.
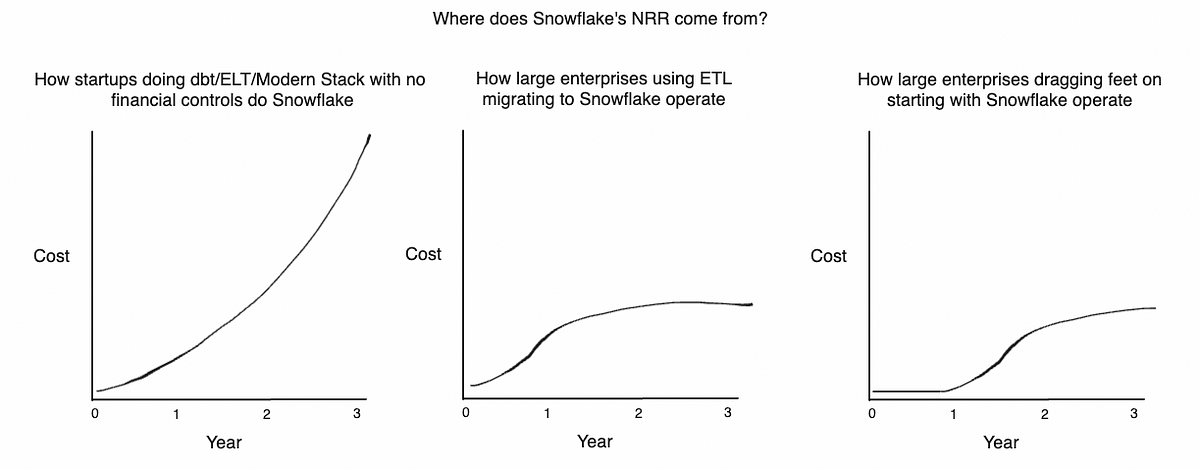
Simultaneously in the market several things are happening:
- New logo adoption and activation to The Data Cloud is decelerating
- The SOM or Serviceable Obtainable Market of customers is becoming more tapped. There simply are not very many new customers to go after.
- All of these satellite point solution data companies like Fivetran and Monte Carlo and Census and dbt Labs and everyone else are incredibly overvalued to the revenue that they actually produce.
So if these companies need to grow revenue or at the very least pump more consumption and cloud credit burn and they cannot get this growth from new customers, where are they going to get it from?
Well, they are going to get incremental revenue from you, the existing customer. How are they going to get more revenue from existing customers? Two ways:
- Raising prices
- Proliferating bad ideas through content and influencers
We’ve already seen everyone from Google Cloud’s BigQuery to dbt Labs announce pricing increases, with dbt Labs’ CEO hilariously claiming that some users actually want to pay more to help the community.
dbt Labs will raise prices on their Cloud offering again. Their valuation is too high, and they don’t make enough money for their burn, and too many of their customers are immature and will bear it because they don’t know what else to do.
Of course they are putting out content trying to normalize the idea that having lots of dbt SQL sequences of models is a good thing. If they can convince enough Heads of Data at companies without accountability or financial controls that this is proper, they’ll have more dbt Cloud to sell and more companies more dependent on dbt Cloud and they’ll kick back more consumption to the cloud.
If you actually have 5,000 models you should be moving a ton of this transform to more efficient compute prior to landing it in Point B. Removing as much dbt as possible is the only way to get out of this high interest, compounding debt obligation.
dbt Labs’ only hope is to go completely delusional with content. Why stop at 5,000 dbt models? Jack up the narrative to 7,500. Hit 10,000. Make content that shows Heads of Data how to get from 800 models to 1,500 in two months so that they need to hire another person or two and build out their fiefdom.
It’s only going to get worse. Playing the delusional angle is the only path they have.
What Makes a Scam a Scam?
Bill Inmon, one of the all-time greats, joined my podcast about a week ago, where we went over the history of data and computing scams, going all the way back to the 1960s.
We covered everything from evaluating vendor claims to chatting about POCs to discussing how industry analysts are paid to make specific recommendations to how untrained people are sitting ducks for data scams. Bill is an absolute treasure and I had a grin on my face most of the conversation.
The conversation begs a few questions. When does something become a scam? If most things are scams or can become scams, what is not a scam?
The answer lies in being smart, acting like a grown-up, and understanding both systems architecture within your organization as well as the pricing models of various vendors. The more you know about this, the more you can avoid getting scammed. If you are not doing this, it’s likely you are actually scamming your own company.
Overcoming linear bias is also critical in avoiding scams. If you can only think linearly, you are at the mercy of anyone selling you anything from a credit card to a data tool. There is an arbitrage in here that credit lenders can exploit, and data tools are no different, especially on consumption models which are quite literally based on credit. This stuff is literally called cloud credits. (I’ll hold my tongue for now on how funny it is that Google Cloud Platform has “slot” machines.)
Why is this all important now more than ever?
For one, all these point solution vendors are screwed when it comes to actually making money and it’s coming to a head.
There is another interesting element at play here which nobody seems to talk about. So I am going to talk about it. It is the fact that people are spending more time at jobs now. In the past few years, people were switching jobs left and right, with many engineers, analysts, data scientists, and even management turning over after 9 months, 12 months, 18 months. When everything is up, up, up it’s easy to leave for seemingly greener pastures because there are so many job openings. The problem with this is that employees and managers working on cloud usage-based models aren’t staying on for full compounding cycles, which crank up in Year 2 or Year 3. These employees will build out a data stack, stay on for a year-and-a-half or two years, and then by the time the debt really starts to compound they are out the door, promoted to be the new Director of Analytics at some other new startup to start the cycle over again. Meanwhile, the employer they just left holds the bag on the interest that was created.
The days of being able to cycle through employers is largely over, at least for now. Now that people are staying longer at jobs they will face more consequences. It’s simply time to start learning how to get out of compounding interest payments. It’s not a refactoring — it’s a refinancing.
So is dbt Labs a scam?
Yeah, pretty much.
See, the less you know about basic finance, the more these guys can take advantage of you and harvest cash flows out of your business for no good reason.
Right now in the market a lot of dbt zealots and dbt-adjacent vendors are cooking up narratives about cost savings.
Do not get me wrong, it’s good to save money, but most of this discourse from this partner crowd is based on paying down interest on dbt, not on paying off the principal. Also, most of the content mill about cost savings is painfully obvious stuff that people should be doing anyway.
Here is an example from Hightouch, America’s Premier Reverse ETL Vendor of Note.

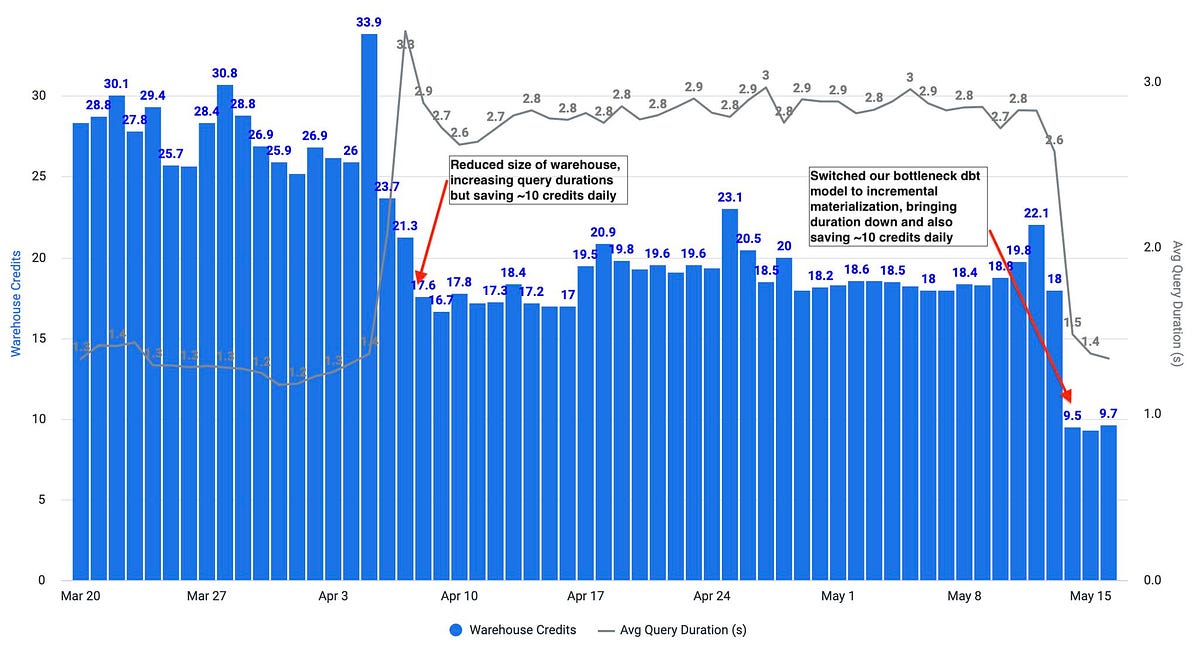
There are all different types of companies out there. Some are ops-led, some are product-led, some are sales-led.
Snowflake is partner-led.
Right here is an example of partners using other partners to partner on controlling a narrative about saving Snowflake costs. It’s nice, but frankly this should be obvious just using Snowflake without the need for other tools.
Net-net, by changing a warehouse size and updating incrementally, Hightouch Reverse ETL has more than halved their warehouse credit burn. Cool.

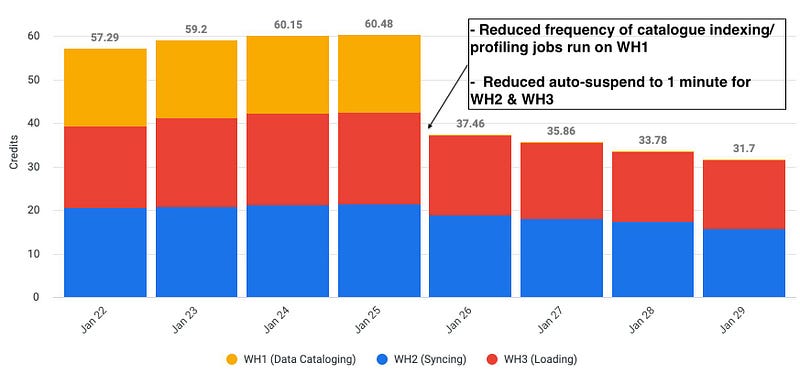
How were Snowflake costs saved here?
Turning off the data catalog. Turning down Snowflake’s rent-taking auto-suspend from 5 minutes to 1 minute.
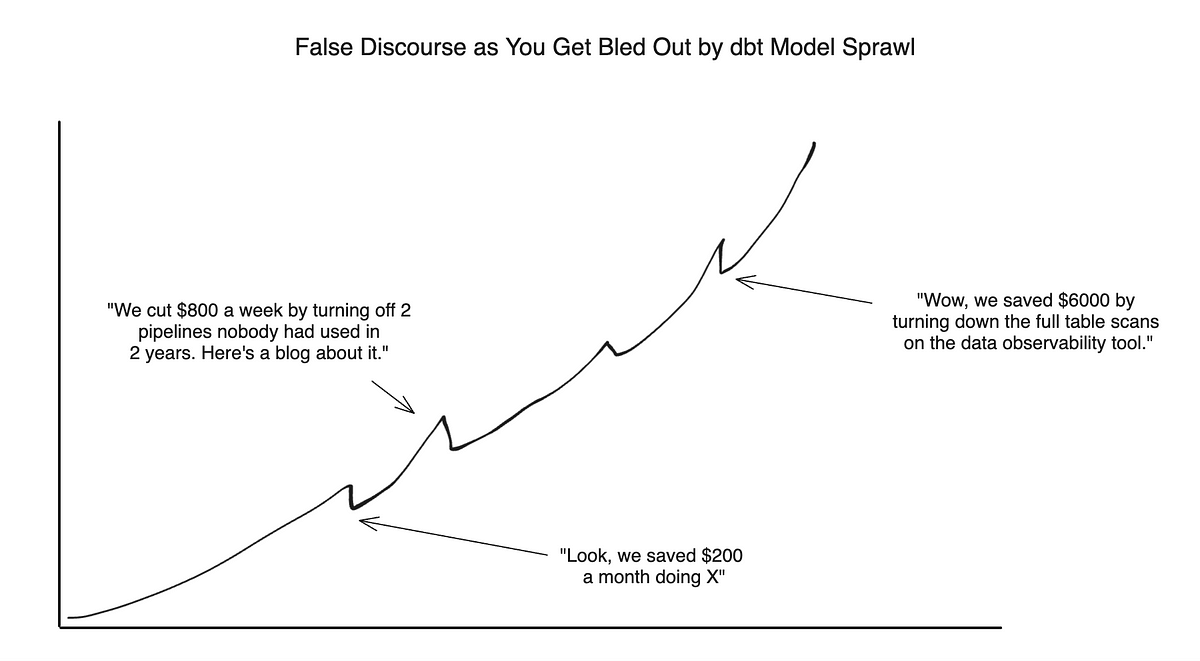
See, these tips and tricks are all symptom relief tactics. The interest is going to creep right back in short order when you have hundreds to thousands of dbt models.
Paying down the principal can involve denormalizing data, shifting Bronze landing layers and Silver staging or intermediary layers left out of Snowflake into an ETL process or tool and only landing Gold tables in Snowflake, and using proper indexing, sorting, and clustering. Paying down the principal means removing most of this intermediary transformation and resolving entities as early as possible.
If this is all too complicated, here’s a great video.
It may shock you. It may frighten you. It’s the video the VCs don’t want you to see!

